An Introduction to Functional Reactive Programming

I gave a talk this year about functional reactive programming (FRP) that attempted to break down what gives FRP its name and why you should care. Here's a write-up of that talk.
Introduction
Functional reactive programming has been all the rage in the past few years. But what is it, exactly? And why should you care?
Even for people who are currently using FRP frameworks like RxJava, the fundamental reasoning behind FRP may be mysterious. I'm going to break down that mystery today, doing so by splitting up FRP into its individual components: reactive programming and functional programming.
Reactive Programming
First, let's take a look at what it means to write reactive code.
Let's start with a simple example: a switch and a light bulb. As you flick the switch, the light bulb turns on and off.
In coding terms, the two components are coupled. Usually you don't give much thought to how they are coupled, but let's dig deeper.
One approach is to have the switch modify the state of the bulb. In this case, the switch is proactive, pushing new states to the bulb; whereas the bulb is passive, simply receiving commands to change its state.
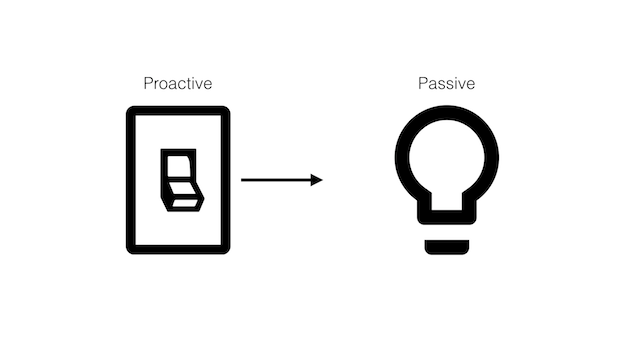
We'll represent this relationship by putting the arrow on the switch - that is, the one connecting the two components is the switch, not the bulb.
Here's a sketch of the proactive solution: the Switch contains an instance of the LightBulb, which it then modifies whenever its state changes.
class Switch {
LightBulb lightBulb;
void onFlip(boolean enabled) {
lightBulb.power(enabled);
}
}
The other way to couple these components would be to have the bulb listen to the state of the switch then modify itself accordingly. In this model, the bulb is reactive, changing its state based on the switch's state; whereas the switch is observable, in that others can observe its state changes.
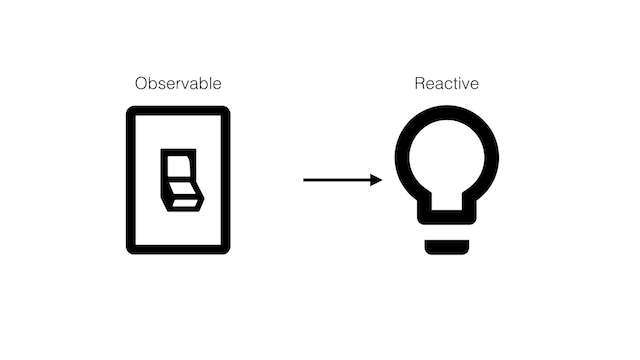
Here's a sketch of the reactive solution: the LightBulb takes in a Switch that it listens to for events, then modifies its own state based on the listener.
static LightBulb create(Switch theSwitch) {
LightBulb lightBulb = new LightBulb();
theSwitch.addOnFlipListener(enabled -> lightBulb.power(enabled));
return lightBulb;
}
To the end user, both the proactive and reactive code lead to the same result. What are the differences between each approach?
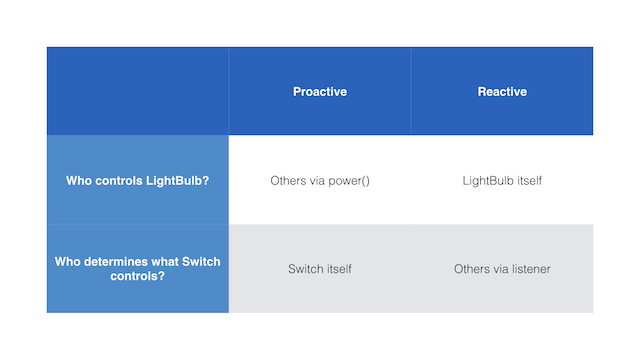
The first difference is who controls the LightBulb. In the proactive model, it must be some external component that calls LightBulb.power(). With reactive, it is the LightBulb itself that controls its luminosity.
The second difference is who determines what the Switch controls. In the proactive model, the Switch itself determines who it controls. In the reactive model, the Switch is ignorant of what it's driving, since others hook into it via a listener.
You get the sense that the two models are mirror images of each other. There's a duality between proactive and reactive coding.
However, there is a subtle difference in how tightly or loosely coupled the two components are. In the proactive model, modules control each other directly. In the reactive model, modules control themselves and hook up to each other indirectly.
Let's see how this plays out in a real-life example. Here's the Trello home screen. It's showing the boards you have from the database. How does this relationship play out with a proactive or reactive model?

With a proactive model, whenever the database changes, it pushes those changes to the UI. But this doesn't make any sense: Why does my database have to care about the UI at all? Why should it have to check if the home screen is being displayed, and know whether it should push new data to it? The proactive model creates a bizarrely tight coupling between my DB and my UI.

The reactive model, by contrast, is much cleaner. Now my UI listens to changes in the database and updates itself when necessary. The database is just a dumb repository of knowledge that provides a listener. It can be updated by anyone, and those changes are simply reflected wherever they are needed in the UI.

This is the Hollywood principle in action: don't call us, we'll call you. And it's great for loosely coupling code, allowing you to encapsulate your components.
We can now answer what reactive programming is: it's when you focus on using reactive code first, instead of your default being proactive code.
Our simple listener isn't great if you want to default to reactive, though. It's got a couple problems:
class Switch {
interface OnFlipListener {
void onFlip(boolean enabled);
}
void addOnFlipListener(OnFlipListener onFlipListener) {
// ...etc...
}
}
First, every listener is unique. We have Switch.OnFlipListener, but that's only usable with Switch. Each module that can be observed must implement its own listener setup. Not only does that mean a bunch of busywork implementing boilerplate code, it also means that you cannot reuse reactive patterns since there's no common framework to build upon.
The second problem is that every observer has to have direct access to the observable component. The LightBulb has to have direct access to Switch in order to start listening to it. That results in a tight coupling between modules, which ruins our goals.
What we'd really like is if Switch.flips() returned some generalized type that can be passed around. Let's figure out what type we could return that satisfies our needs.
class Switch {
??? flips() {
// ...etc...
}
}
There are four essential objects that a function can return. On one axis is how many of an item is returned: either a single item, or multiple items. On the other axis is whether the item is returned immediately (sync) or if the item represents a value that will be delivered later (async).

The sync returns are simple. A single return is of type T: any object. Likewise, multiple items is just an Iterable<T>.

It's simple to program with synchronous code because you can start using the returned values when you get them, but we're not in that world. Reactive coding is inherently asynchronous: there's no way to know when the observable component will emit a new state.
As such, let's examine async returns. A single async item is equivalent to Future<T>. Good, but not quite what we want yet - an observable component may have multiple items (e.g., Switch can be flicked on/off many times).
What we really want is in that bottom right corner. What we're going to call that last quadrant is an Observable<T>. An Observable is the basis for all reactive frameworks.

Let's look at how Observable<T> works in practice:
class Switch {
Observable<Boolean> flips() {
// ...etc...
}
}
// Creating the LightBulb...
static LightBulb create(Observable<Boolean> observable) {
LightBulb lightBulb = new LightBulb();
observable.subscribe(enabled -> lightBulb.power(enabled));
return lightBulb;
}
In our new code, Switch.flips() returns an Observable<Boolean> - that is, a sequence of true/false that represents the state of the Switch. Now our LightBulb, instead of consuming the Switch directly, will subscribe to an Observable<Boolean> that the Switch provides.
This code behaves the same as our non-Observable code, but fixes the two problems I outlined earlier. Observable<T> is a generalized type, allowing us to build upon it. And it can be passed around, so our components are no longer tightly coupled.
Let's solidify the basics of what an Observable is. An Observable is a collection of items over time.
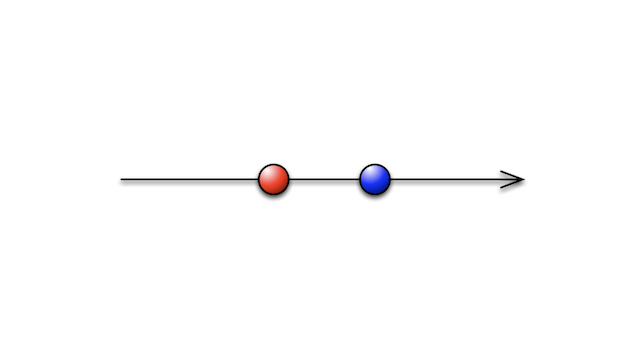
What I'm showing here is a marble diagram. The line represents time, whereas the circles represent events that the Observable would push to its subscribers.
Observable can result in one of two possible terminal states as well: successful completions and errors.
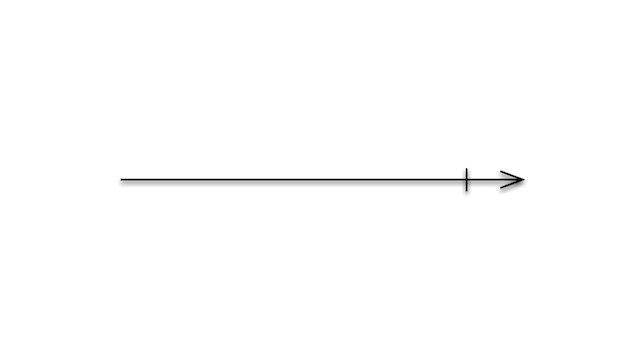
A successful completion is represented by a vertical line in the marble diagram. Not all collections are infinite and it is necessary to be able to represent that. For example, if you are streaming a video on Netflix, at some point that video will end.
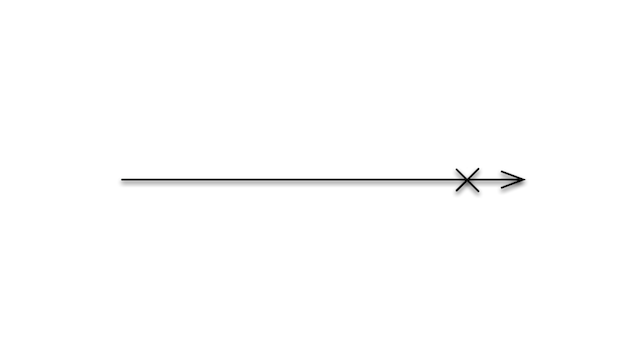
An error is represented by an X and is the result of the stream of data becoming invalid for some reason. For example, if someone took a sledgehammer to our switch, then it's worth informing everyone that our switch has not only stopped emitting any new states, but that it isn't even valid to listen to anymore because it's broken.
Functional Programming
Let's set aside reactive programming for a bit and jump into what functional programming entails.
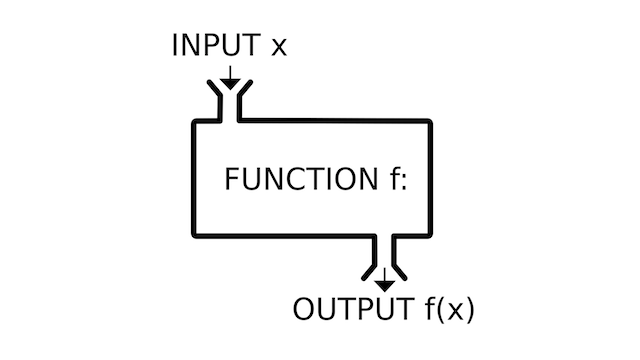
Functional programming focuses on functions. Duh, right? Well, I'm not talking about any plain old function: we're cooking with pure functions.
Let me explain what a pure function is through counter-example.
int two = add(1, 1);
static int add(int a, int b) {
return a + b;
}
Suppose we have this perfectly reasonable add() function which adds two numbers together. But wait, what's in all that empty space in the function?
static int add(int a, int b) {
System.out.println("You're an idiot for using this function!");
return a + b;
}
Oops! It looks like add() sends some text to stdout. This is what's known as a side effect. The goal of add() is not to print to stdout; it's to add two numbers. Yet it's modifying the global state of the application.
But wait, there's more.
static int add(int a, int b) {
System.out.println("You're an idiot for using this function!");
System.exit(1010101);
return a + b;
}
Ouch! Not only does it print to stdout, but it also kills the program. If all you did was look at the function definition (two ints in, one int out) you would have no idea what devastation using this method would cause to your application.
Let's look at another example.
List<Integer> numbers = new ArrayList<>(Arrays.asList(1, 2, 3));
boolean sumEqualsProduct = sum(numbers) == product(numbers);
Here, we're going to take a list and see if the sum of the elements is the same as the product. I would think this would be true for [1, 2, 3] because 1 + 2 + 3 == 6 and 1 * 2 * 3 == 6.
static int sum(List<Integer> numbers) {
int total = 0;
Iterator<Integer> it = numbers.iterator();
while(it.hasNext()) {
total += it.next();
it.remove(); // UH OH
}
return total;
}
However, check out how the sum() method is implemented. It doesn't affect the global state of our app, but it does modify one of its inputs! This means that the code will misfire, because by the time product(numbers) is run, numbers will be empty. While rather contrived, this sort of problem can come up all the time in actual, impure functions.

A side effect occurs anytime you change state external to the function. As you can see by now, side effects can make coding difficult. Pure functions do not allow for any side effects.
Interestingly, this means that pure functions must return a value. Having a return type of void would mean that a pure function would do nothing, since it cannot modify its inputs or any state outside of the function.
It also means that your function's inputs must be immutable. We can't allow the inputs to be mutable; otherwise concurrent code could change the input while a function is executing, breaking purity. Incidentally, this also implies that outputs should also be immutable (otherwise they can't be fed as inputs to other pure functions).
There's a second aspect to pure functions, which is that given the same inputs, they must always return the same outputs. In other words, they cannot rely on any external state to the function.
String createGreeting(String name) {
if (Math.random() > .5) {
return "Hello, " + name;
}
else {
return "Greetings, " + name;
}
}
For example, check out this function that greets a user. It doesn't have any side effects, but it randomly returns one of two greetings. The randomness is provided via an external, static function.
This makes coding much more difficult for two reasons. First, the function has inconsistent results regardless of your input. It's a lot easier to reason about code if you know that the same input to a function results in the same output. And second, you now have an external dependency inside of a function; if that external dependency is changed in any way, the function may start to behave differently.
What may be confusing to the object-oriented developer is that this means a pure function cannot even access the state of the class it is contained within. For example, Random's methods are inherently impure because they return new values on each invocation, based on Random's internal state.
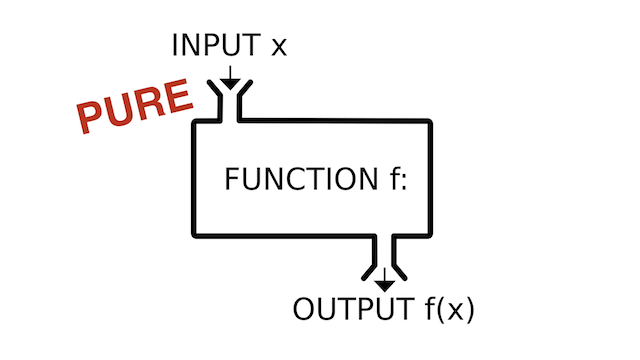
In short: functional programming is based on pure functions. Pure functions are ones that don't consume or mutate external state - they depend entirely on their inputs to derive their output.
One point of confusion that often hits people first introduced to FP: how do you mutate anything? For example, what if I want to take a list of integers and double all their values? Surely you have to mutate the list, right?
static List<Integer> doubleValues(List<Integer> input) {
List<Integer> output = new ArrayList<>();
for (Integer value : input) {
output.add(value * 2);
}
return output;
}
Well, not quite. You can use a pure function that transforms the list for you. Here's a pure function that doubles the values of a list. No side effects, no external state, and no mutation of inputs/outputs. The function does the dirty mutation work for you so that you don't have to.
However, this method we've written is highly inflexible. All it can do is double each number in an array, but I can imagine many other manipulations we could do to an integer array: triple all values, halve all values... the ideas are endless.
Let's write a generalized integer array manipulator. We'll start with a Function interface; this allows us to define how we want to manipulate each integer.
interface Function {
Integer apply(Integer int);
}
Then, we'll write a map() function that takes both the integer array and a Function. For each integer in the array, we can apply the Function.
static List<Integer> map(List<Integer> input,
Function fun) {
List<Integer> output = new ArrayList<>();
for (Integer value : input) {
output.add(fun.apply(value));
}
return output;
}
Voila! With a little extra code, we can now map any integer array to another integer array.
List<Integer> numbers = Arrays.asList(1, 2, 3);
List<Integer> doubled = map(numbers, i -> i * 2);
We can take this example even further: why not use generics so that we can transform any list from one type to another? It's not so hard to change the previous code to do so.
interface Function<T, R> {
R apply(T t);
}
static <T, R> List<R> map(List<T> input,
Function<T, R> fun) {
List<R> output = new ArrayList<>();
for (T value : input) {
output.add(fun.apply(value));
}
return output;
}
Now, we can map any List<T> to List<R>. For example, we can take a list of strings and convert it into a list of each string's length:
List<String> words = Arrays.asList("one", "two", "three");
List<Integer> lengths = map(words, s -> s.length());
Our map() is known as a higher-order function because it takes a function as a parameter. Being able to pass around and use functions is a powerful tool because it allows code to be much more flexible. Instead of writing repetitious, instance-specific functions, you can write generalized functions like map() that are reusable in many circumstances.
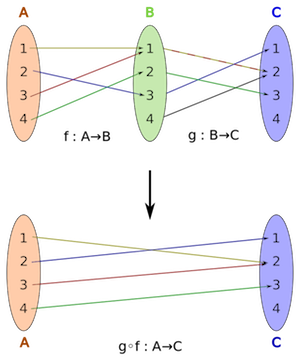
Beyond just being easier to work with due to a lack of external state, pure functions also make it much easier to compose functions. If you know that one function is A -> B and another is B -> C, we can then stick the two functions together to create A -> C.
While you could compose impure functions, there are often unwanted side effects that occur, meaning it's hard to know if composing functions will work correctly. Only pure functions can assure coders that composition is safe.
Let's look at an example of composition. Here's another common FP function - filter(). It lets us narrow down the items in a list. Now we can filter our list before transforming it by composing the two functions.
interface Predicate<T> {
boolean test(T t);
}
static <T> List<T> filter(List<T> input, Predicate<T> predicate) {
List<T> output = new ArrayList<>();
for (T value : input) {
if (predicate.test(value)) {
output.add(value);
}
}
return output;
}
List<Integer> input = Arrays.asList(1, 4 15, 16, 23);
List<Integer> oddValues = filter(input, i -> i % 2 == 1);
List<Integer> doubled = map(oddValues, i -> i * 2);
We now have a couple small but powerful transformation functions, and their power is increased greatly by allowing us to compose them together.
There is far more to functional programming than what I've presented here, but this crash course is enough to understand the "FP" part of "FRP" now.
Functional Reactive Programming
Let's examine how functional programming can augment reactive code.
Suppose that our Switch, instead of providing an Observable<Boolean>, instead provides its own enum-based stream Observable<State>.
class Switch {
enum State {
ON,
OFF
}
Observable<State> flips() {
// ...etc...
}
}
static LightBulb create(Observable<Boolean> observable) {
LightBulb lightBulb = new LightBulb();
observable.subscribe(enabled -> lightBulb.power(enabled));
return lightBulb;
}
There's seemingly no way we can use Switch for our LightBulb now since we've got incompatible generics. Switch.flips() returns Observable<State> but LightBulb.create() requires Observable<Boolean>. But there is an obvious way that Observable<State> mimics Observable<Boolean> - what if we could convert from a stream of one type to another?
Remember the map() function we just saw in FP? It converts a synchronous collection of one type to another. What if we could apply the same idea to an asynchronous collection like an Observable?
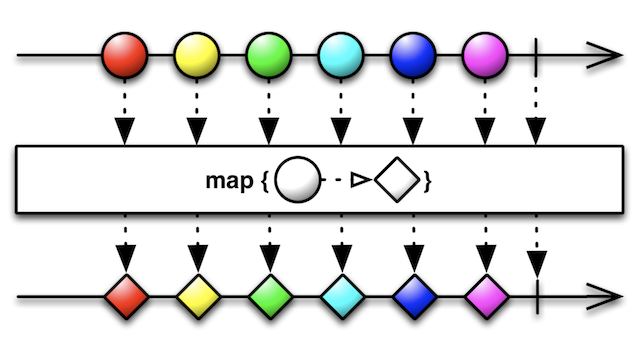
Ta-da: here's map(), but for Observable. Observable.map() is what's known as an operator. Operators let you transform an Observable stream in basically any way imagineable.
The marble diagram for an operator is a bit more complex than what we saw before. Let's break it down:
- The top line represents the input stream: a series of colored circles.
- The middle box represents the operator: converts a circle to a square.
- The bottom line represents the output stream: a series of colored squares.
Essentially, it's a 1:1 conversion of each item in the input stream.
Let's apply that to our switch problem. We start with an Observable<State>. Then we use map() so that every time a new State is emitted it's converted to a Boolean; thus map() returns Observable<Boolean>. Now that we have the correct type, we can construct our LightBulb.
Switch theSwitch = new Switch();
Observable<State> stateObservable = theSwitch.flips();
Obsevable<Boolean> booleanObservable = stateObservable
.map(state -> state == State.ON);
LightBulb.create(booleanObservable);
Alright, that's useful. But what does this have to do with pure functions? Couldn't you write anything inside map(), including side effects? Sure, you could... but then you make the code difficult to work with. Plus, you miss out on some side-effect-free composition of operators.
Imagine our State enum has more than two states, but we only care about the fully on/off state. In that case, we want to filter out any in-between states.
class Switch {
enum State {
ON,
HALFWAY,
OFF
}
// ...etc...
}
Oh look, there's a filter() operator in FRP as well; we can compose that with our map() to get the results we want.
Switch theSwitch = new Switch();
Observable<State> stateObservable = theSwitch.flips();
Obsevable<Boolean> booleanObservable = stateObservable
.filter(state -> state != State.HALFWAY)
.map(state -> state == State.ON);
LightBulb.create(booleanObservable);
If you compare this FRP code to the FP code I had in the previous section, you'll see how remarkably similar they are. The only difference is that the FP code was dealing with a synchronous collection, whereas the FRP code is dealing with an asynchronous collection.
There are a ton of operators in FRP, covering many common cases for stream manipulation, that can be applied and composed together. Let's look at a real-life example.
The Trello main screen I showed before was quite simplified - it just had a big arrow going from the database to the UI. But really, there are a bunch of sources of data that our home screen uses.
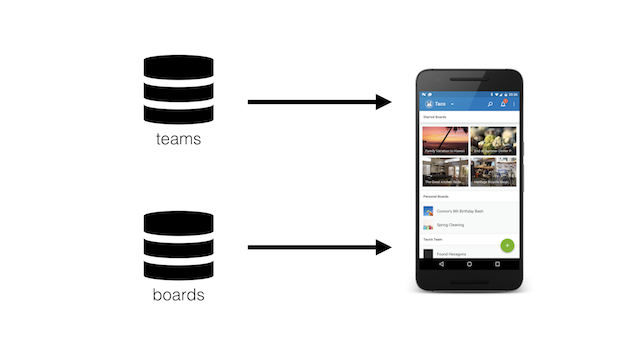
In particular, we've got source of teams, and inside of each team there can be multiple boards. We want to make sure that we're receiving this data in sync; we don't want to have mismatched data, such as a board without its parent team.
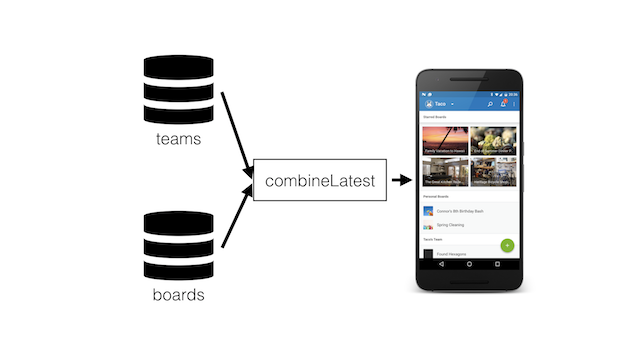
To solve this problem we can use the combineLatest() operator, which takes multiple streams and combines them into one compound stream. What is particularly useful is that it updates every time any of its input streams update, so we can ensure that the packaged data we send to the UI is complete and up-to-date.

There really are a wealth of operators in FRP. Here's just a few of the useful ones... often, when people first get involved with FRP they see the list of operators and faint.
However, the goal of these operators isn't to overwhelm - it's to model typical flows of data within an application. They're your friends, not your enemies.
My suggestion for dealing with this is to take it one step at a time. Don't try to memorize all the operators at once; instead, just realize that an operator probably already exists for what you want to do. Look them up when you need them, and after some practice you'll get used to them.
Takeaway
I endeavored to answer the question "what is functional reactive programming?" We now have an answer: it's reactive streams combined with functional operators.
But why should you try out FRP?
Reactive streams allow you to write modular code by standardizing the method of communication between components. The reactive data flow allows for a loose coupling between these components, too.
Reactive streams are also inherently asynchronous. Perhaps your work is entirely synchronous, but most applications I've worked on depend on asynchronous user-input and concurrent operations. It's easier to use a framework which is designed with asynchronous code in mind than try to write your own concurrency solution.
The functional part of FRP is useful because it gives you the tools to work with streams in a sane manner. Functional operators allow you to control how the streams interact with each other. It also gives you tools for reproducing common logic that comes up with coding in general.
Functional reactive programming is not intuitive. Most people start by coding proactively and impurely, myself included. You do it long enough and it starts to solidify in your mind that proactive, impure coding is the only solution. Breaking free of this mindset can enable you to write more effective code through functional reactive programming.
Resources
I want to thank/point out some resources I drew upon for this talk.
-
cycle.js has a great explanation of proactive vs. reactive code, which I borrowed from heavily for this talk.
-
Erik Meijer gave a fantastic talk on the proactive/reactive duality. I borrowed the four fundamental effects of functions from here. The talk is quite mathematical but if you can get through it, it's very enlightening.
-
If you want to get more into functional programming, I suggest trying using an actual FP language. Haskell is particularly illuminating because of its strict adherence to FP, which means you can't cheat your way out of actually learning it. "Learn you a Haskell" is a good, free online book if you want to investigate further.
-
If you want to learn more about FRP, check out my own series of blog posts about it. Some of the topics covered in those posts are covered here, so reading both would be a bit repetitive, but it goes into more details on RxJava in particular.