How Trello Android converted from Gson to Moshi

Trello Android recently converted from using Gson to Moshi for handling JSON. It was a bit tricky so I wanted to document the process.
(For context, Trello Android primarily parses JSON. We rarely serialize JSON, and thus most of the focus here is on deserializing.)
Why Refactor?
There were three main reasons for the switch from Gson to Moshi: safety, speed, and bad life choices.
Safety - Gson does not understand Kotlin’s null safety and will happily place null values into non-null properties. Also, default values only sometimes work (depending on the constructor setup).
Speed - Plenty of benchmarks (1, 2, 3) have demonstrated that Moshi is usually faster than Gson. After we converted, we set up some benchmarks to see how real-world parsing compared in our app, and we saw a 2x-3.5x speedup:
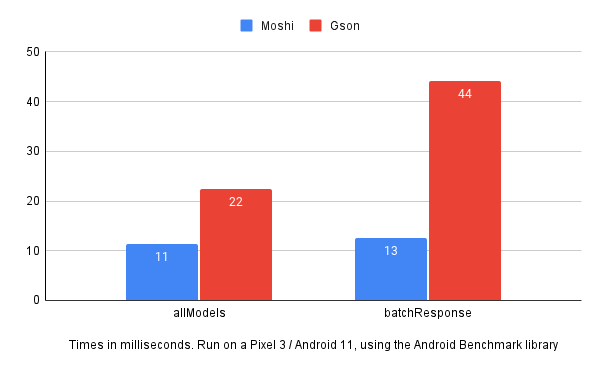
Bad life choices - Instead of using Gson to parse JSON into simple models, we would write elaborate, confusing, brittle custom deserializers that had entirely too much logic in them. Refactoring gave us an opportunity to correct this architectural snafu.
As for why we picked Moshi over competitors (e.g. Kotlin serialization), we generally trust Square's libraries, we've used Moshi in the past for projects (both at work and at home) and felt it worked well. We did not do an in-depth study of alternatives.
Step 1 - Feature Flags
The first step was to ensure that we could use feature flags to switch between using our old Gson implementation and the new Moshi one. I wrote a JsonInterop class which, based on the flag, would either parse all JSON responses using Gson or Moshi.
(I opted to avoid using tools like moshi-gson-interop because I wanted to test whether Moshi parsing worked in its entirety. If you’d rather have a mix of Gson and Moshi at the same time, that library would be useful.)
Step 2 - Safety Checks
Gson gives you opportunities to override the default naming of a key using @SerializedName. Moshi lets you do the same thing with @Json. That's all well and good, but it seemed really easy to me to make a mistake here, where a property is parsed under different names in Gson vs. Moshi.
Thus, I wrote some unit tests that would verify that our generated Moshi adapters would have the same outcome as Gson’s parsing. In particular, I tested...
- ...that Moshi could generate an adapter (not necessarily a correct one!) for each class we wanted to deserialize. (If it couldn't, Moshi would throw an exception.)
- ...that each field annotated with
@SerializedNamewas also annotated with@Json(using the same key).
Between these two checks, it was easy to find when I’d made a mistake updating our classes in later steps.
(I can’t include the source here, but basically we used Guava’s ClassPath to gather all our classes, then scan through them for problems.)
Step 3 - Remove Gson-Specific Classes
Gson allows you to parse generic JSON trees using JsonElement (and friends). We found this useful in some contexts like parsing socket updates (where we wouldn’t know how, exactly, to parse the response model until after some initial processing).
Obviously, Moshi is not going to be happy about using Gson’s classes, so we switched to using Map<String, Any?> (and sometimes List<Map<String, Any?>>) for generic trees of data. Both Gson and Moshi can parse these:
fun <T> fromJson(map: Map<String, Any?>?, clz: Class<T>): T? {
return if (USE_MOSHI) {
moshi.adapter(clz).fromJsonValue(map)
}
else {
gson.fromJson(gson.toJsonTree(map), clz)
}
}In addition, Gson is friendly towards parsing via Readers, but Moshi is not. I found that using BufferedSource was a good alternative, as it can be converted to a Reader for old Gson code.
Step 4 - Create Moshi Adapters
The easiest adapters for Moshi are the ones where you just slap @JsonClass on them and call it a day. Unfortunately, as I mentioned earlier, we had a lot of unfortunate custom deserialization logic in our Gson parser.
It’s pretty easy to write a custom Moshi adapter, but because there was so much custom logic in our deserializers, just writing a single adapter wouldn’t cut it. We ended up having to create interstitial models to parse the raw JSON, then adapt from that to the models we’re used to using.
To give a concrete example, imagine we have a data class Foo(val count: Int), but the actual JSON we get back is of the form:
{
"data": {
"count": 5
}
}With Gson, we could just manually look at the tree and grab the count out of the data object, but we have discovered that way lies madness. We'd rather just parse using simple POJOs, but we still want to output a Foo in the end (so we don't have to change our whole codebase).
To solve that problem, we’d create new models and use those in custom adapter, like so:
@JsonClass(generateAdapter = true) data class JsonFoo(val data: JsonData)
@JsonClass(generateAdapter = true) data class JsonData(val count: Int)
object FooAdapter {
@FromJson
fun fromJson(json: JsonFoo): Foo {
return Foo(count = json.data.count)
}
}Voila! Now the parser can still output Foo, but we’re using simple POJOs to model our data. It’s both easier to interpret and easy to test.
Step 5 - Iron Out Bugs
Remember how I said that Gson will happily parse null values into non-null models? It turns out that we were (sadly) relying on this behavior in all sorts of places. In particular, Trello’s sockets often return partial models - so while we’d normally expect, say, a card to come back with a name, in some cases it won’t.
That meant having to monitor our crashes for cases where the Moshi would blow up (due to a null value) when Gson would be happy as a clam. This is where feature flags really shine, since you don’t want to have to push a buggy parser on unsuspecting production users!
After fixing a dozen of these bugs, I feel like I’ve gained a hearty appreciation for non-JSON technologies with well-defined schemas like protocol buffers. There are a lot of bugs I ran into that simply wouldn’t have happened if we had a contract between the server and the client.